Warum ein Telugu-Charakter Apple-Geräte brucht
Apple hatte ein paar Monate Buggy. Jetzt haben wir einen neuen, ernsten Fehler in der Text-Rendering-Funktionalität in iPhones. Der Bug wird durch ein einzelnes Telugu-Zeichen ausgelöst, das dazu führen kann, dass ein iPhone in eine unzerbrechliche Boot-Schleife gelangt, indem es eine Benachrichtigung erhält, die das Zeichen enthält. Schauen wir uns an, warum ein einzelnes Zeichen so große Probleme mit iOS verursachen kann.
Hinweis: Eine Fehlerbehebung für den Telugu-Fehler ist in der neuesten Version von iOS (11.2.6) verfügbar. Wenn der Telugu-Charakter Ihre App oder Ihr Gerät gesperrt hat, stellen Sie Ihr iPhone über iTunes wieder her und aktualisieren Sie es auf die neueste Version von iOS. Wenn sich Ihr iPhone in einer Startschleife befindet, müssen Sie es möglicherweise in den Geräte-Firmware-Update-Status (DFU) versetzen, damit iTunes es erkennt. Wenn Sie fertig sind, stellen Sie Ihr Gerät von Ihrer letzten Sicherung wieder her, die Sie hoffentlich erstellt haben.
Was ist Telugu?

Telugu ist eine Sprache, die in Teilen Indiens gesprochen und geschrieben wird, insbesondere in den Bundesstaaten Andhra Pradesh, Telangana und in der Stadt Yanam. Wie viele Skript-basierte Sprachen, wie Arabisch und andere Brahmanic-Skripte, verwendet Telugu einige spezielle Funktionen des Unicode-Zeichensatzes, um seine Zeichen auf einem Computerbildschirm anzuzeigen.
Während die meisten lateinischen Buchstaben durch einen einzelnen 8-Bit-Unicode-Codepunkt für ASCII-Kompatibilität dargestellt werden (zum Beispiel existiert der Buchstabe A am Unicode-Codepunkt U+0041, der binär durch 01000001 repräsentiert wird), Sprachen, die mit Skript oder nicht geschrieben sind Lateinische Buchstaben kombinieren normalerweise mehr als einen Unicode-Codepunkt, um ihre Zeichen darzustellen.
Dies gilt insbesondere für Sprachen wie Telugu, die die Sprachversionen von Buchstaben in Clustern kombinieren. Im Gegensatz zu den stilistischen Ligaturen des Englischen ist die Verbindung zwischen jedem Telugu-Buchstaben sprachlich wichtig. Um dies zu ermöglichen, enthält Unicode ein komplexes System zum Anfügen von Zeichen, die jeweils durch einen eigenen Codepunkt repräsentiert werden.
Angesichts der schieren Anzahl von Unicode-Codepunkten kann dies nahezu unendliche Vielfalt erzeugen. Diese Punkte verbinden sich zu einem lesbaren Charakter. Auf diese Weise benötigt Unicode keinen Unicode-Codepunkt für buchstäblich jedes mögliche Telugu-Wort. Stattdessen kombiniert Unicode Telugu-Konsonanten, Vokale und diakritische Zeichen ("virama"), um Wörter zu erzeugen, die wie ein einzelnes Zeichen dargestellt werden. Gleiches gilt für andere Sprachen mit orthographischen Regeln für Ligaturen, wie Arabisch.
Was verursacht den Absturz?

Das Problem scheint mit dem Zero Width Non-Joiner (ZWNJ) am Codepunkt U+200C . Der ZWNJ fordert, dass zwei benachbarte Zeichen ohne ihre typische Ligatur rendern. Im Englischen hält ein ZWNJ die Buchstaben ff davon ab, mit ihrer Standardverbindungsligatur gedruckt zu werden, sondern trennt jede f voneinander. Aber in Kombination mit einem bestimmten Satz von vier Telugu-Codepunkten (die alle zu einem einzigen Cluster zusammengefasst werden sollten) kann iOS das Ergebnis aus bestimmten Gründen nicht korrekt anzeigen.
Einige haben spekuliert, dass Apples San Francisco Schriftart den Charakter nicht anzeigen kann, während andere gesagt haben, dass der spezifische Renderprozess, den Apple verwendet, schuld ist. Was auch immer die genaue Ursache sein mag, der Versuch, das Zeichen zu rendern, verursacht einen dramatischen Absturz dessen, was es rendert, von Nachrichten und WhatsApp zu Springboard. Die Unicode-Codepunkte, aus denen das Zeichen besteht ("gya" bedeutet "Wissen"), sind unten:
U+0C1Cja (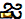 )
)U+0C4Deine Virama oder diakritische Markierung ( )
)U+0C1ENya (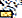 )
)U+200CNullbreite Nicht-TischlerU+0C3Eaa (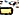 )
)
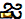 )
) )
)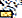 )
)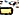 )
)Aber wir können Zero Width Non-Joiner (ZWNJ) nicht einmal allein beschuldigen. Es wird auch in der harmlosen Familie Emojis (????) Ohne Problem verwendet. Es scheint sich um eine spezifische Kombination einiger spezifischer Codepunkte und des ZWNJ zu handeln. Wenn man der Verletzung eine Beleidigung hinzufügt, scheint es so zu sein, dass der ZWNJ entweder keinen besonderen Effekt auf das Rendering auf diesem Telugu-Cluster hat oder dass er gar nicht erst da ist.
Andere Brahmic Script Probleme
Telugu ist jedoch nicht die einzige Sprache mit diesem Thema. Bengali und Devanagari, die Unicode in ähnlicher Weise für ihre Brahmic-Skripte verwenden, haben das gleiche Problem. Manish Goregaokar schreibt einen faszinierenden und detaillierten Blog-Beitrag, der den genauen Crash-Fall noch weiter bricht:
Jede Sequenz
in Devanagari, Bengali und Telugu, wo:1.
consonant2ist Suffix-Beitritt (pstf/vatu)
2.consonant1ist kein reformierender Brief
3.vowelhat nicht zwei Glyph-Komponenten
Fazit: Warum wurde das nicht von Apple abgefangen?
Um zu verstehen, wie dieser Bug durchkam, müssen Sie sich in Apples Schuhe stecken. Sicher, diese Zeichenkombination ist kein sehr unklares Wort in der Telugu-Sprache. Aber das iPhone bietet Unterstützung für Dutzende von Sprachen. Es gibt buchstäblich Milliarden von möglichen Kombinationen in Unicode. Mit dieser großen Vielfalt würde ein sinnvolles Testen von Unicode-Fehlern vor einer Veröffentlichung regelmäßige Software-Updates praktisch unmöglich machen.
Der Fehler sollte jedoch nicht so viel Schaden verursacht haben. Telefone sollten nicht basierend auf dem Inhalt einer Textnachricht gemauert werden. Während Rückblick sicherlich 20/20 ist, scheint es, als ob der Charakter als ein Fragezeichen-Feld ( ) besser gewesen wäre, als Springboard abzustürzen.